14 Prosodische Kennzeichen des Deutschen
14.1 Segmentale und nicht-segmentale phonologische Erscheinungen
14.2.2 Der Silbenaufbau im Sprachvergleich
14.3.1 Akzentuierung von Wörtern
14.3.2 Rhythmus und Gewichtung
14.4.1 Zur Notation von Tonhöhenverläufen
14.4.3 Fallende Endtonverläufe
14.4.4 Steigende Endtonverläufe
14.4.5 Progrediente Endtonverläufe
14.5 Prosodische Phänomene und Gestik
14.6 Prosodie als Thema für Deutsch als Fremd- und Zweitsprache
14.1 Segmentale und nicht-segmentale phonologische Erscheinungen
Mit dem Ausdruck „Prosodie“ bezieht man sich auf phonologische Erscheinungen, die über den Einzellaut hinausgehen. Man spricht in diesem Zusammenhang auch von nicht-segmentaler Phonologie in Absetzung von der Untersuchung einzelner Laute als Segmente des Lautstroms. Die Besonderheit von nicht-segmentalen Phänomenen wird in einer Gegenüberstellung von so genannten Tonsprachen und Intonationssprachen deutlich. In Tonsprachen, wie z. B. dem Chinesischen, besitzen Tonhöhenveränderungen bedeutungsunterscheidende Qualität, ebenso wie Phoneme. Parallel spricht man von Tönen oder auch von Tonemen. Toneme stehen zueinander in phonologischem Kontrast. Die europäisch-schriftsprachlich erfasste Silbe „ma“ entspricht im Chinesischen vier Phonemfolgen mit unterschiedlichen Tönen (flach, steigend, fallend-steigend, fallend), die jeweils eine andere Wortbedeutung haben (Mutter / Amme, Hanf, Pferd, schimpfen). Zusätzlich existiert noch ein tonloses Wort [ma] mit grammatisch-pragmatischer Bedeutung als Kennzeichnung einer Frage.
Chinesisch gehört zu den Konturtonsprachen, in denen sich die Töne als Bewegung erfassen lassen. Dagegen sind Toneme in einer Registertonsprache durch den relativen Abstand zwischen einzelnen Tönen charakterisiert, z. B. im Japanischen, das zwischen „hoch“ und „tief“ unterscheidet. Deutsch wird als Intonationssprache klassifiziert. Töne spielen darin im Allgemeinen keine Rolle. Nur bei einem kleinen Teilbereich, Interjektionen wie hm oder ah, lässt sich ein reduziertes Tonsystem feststellen (s. Kap. 16).[ 1 ]
Während Toneme qualitativ den Phonemen gleichgestellt sind, erfüllen Tonhöhenveränderungen in Intonationssprachen andere Zwecke. Als nicht-segmentale Einheiten eigenen Typs „überlagern“ [ 2 ] sie die lautlichen Segmente einer Sprache; man spricht daher auch oft von Suprasegmentalia. Von manchen Phonologen wird diese Bezeichnung allerdings abgelehnt, denn sie unterstellt eine selbständige Existenz der Prosodie; tatsächlich sei es aber so, dass prosodische Spracheigenschaften auch schon die Lautung mitbestimmen. Die wichtigsten nicht-segmentalen phonologischen Erscheinungen im Deutschen sind
- die Akzentuierung sowie
- die Tonhöhenbewegung in einer Äußerung (Stimmführung, Melodie). Letztere wird (traditionell) auch als „Satzintonation“ bezeichnet.
Akzentuierung und Tonhöhenverläufe sind miteinander verbunden und operieren auf der Einheit „Silbe“.
14.2 Die Silbe
Die Silbe ist eine etwas rätselhafte sprachliche Einheit. Einerseits erkennen Sprecher intuitiv, dass Wörter wie Student aus zwei, Vorlesung aus drei, Sprachwissenschaft aus vier und Wintersemester aus fünf Silben bestehen. Kinder können Silben beim Sprechen mitklatschen, denn sie sind der Wahrnehmung deutlich leichter zugänglich als die Laute, aus denen sie sich zusammensetzen. Welche sprachliche Funktion diese Einheit besitzt, ist weniger deutlich. Die Silbe ist nicht bedeutungstragend. Zwar stimmt ein einsilbiges Wort wie Brot mit einem Morphem überein, trotzdem handelt es sich um verschiedene Grundeinheiten. Anders als der Laut ist die Silbe nicht einmal bedeutungsdifferenzierend. Sie kann nur als rhythmische Größe bestimmt werden.
In manchen Sprachen, z. B. dem Chinesischen, bestehen Wörter (Wortstämme, Wurzeln) überwiegend nur aus einer Silbe, d. h. sie sind monosyllabisch. In anderen Sprachen, so auch dem Deutschen, können Wörter aus mehreren Silben bestehen, d. h. polysyllabisch sein. Bei vielen Wörtern ergeben sich Unterschiede zwischen Silbenstruktur und Morphemstruktur. So umfasst das Wort denken die Morpheme denk- und -en, die Silbenstruktur hingegen ist mit den.ken anzugeben. Im Deutschen sind die Regeln der Worttrennung am Ende einer Schreibzeile an den Silben orientiert, im Englischen an der Einheit Morphem, vgl. dt. ge-ge-ben vs. engl. giv-en.
14.2.1 Der Aufbau der Silbe
Die Baustruktur von Silben in verschiedenen Sprachen ist unterschiedlich. In allen Sprachen besitzt die Silbe einen Silbenkern (Nukleus) mit höchster Schallfülle. Dies ist typischerweise ein Vokal. Um diesen Kern herum können sich Konsonanten gruppieren. Man bezeichnet sie als „Schale“ (s. Abb. 1).
Abb. 1: Silbenaufbau (Nukleus, Schale, Körper und Reim, Einsatz und Coda)
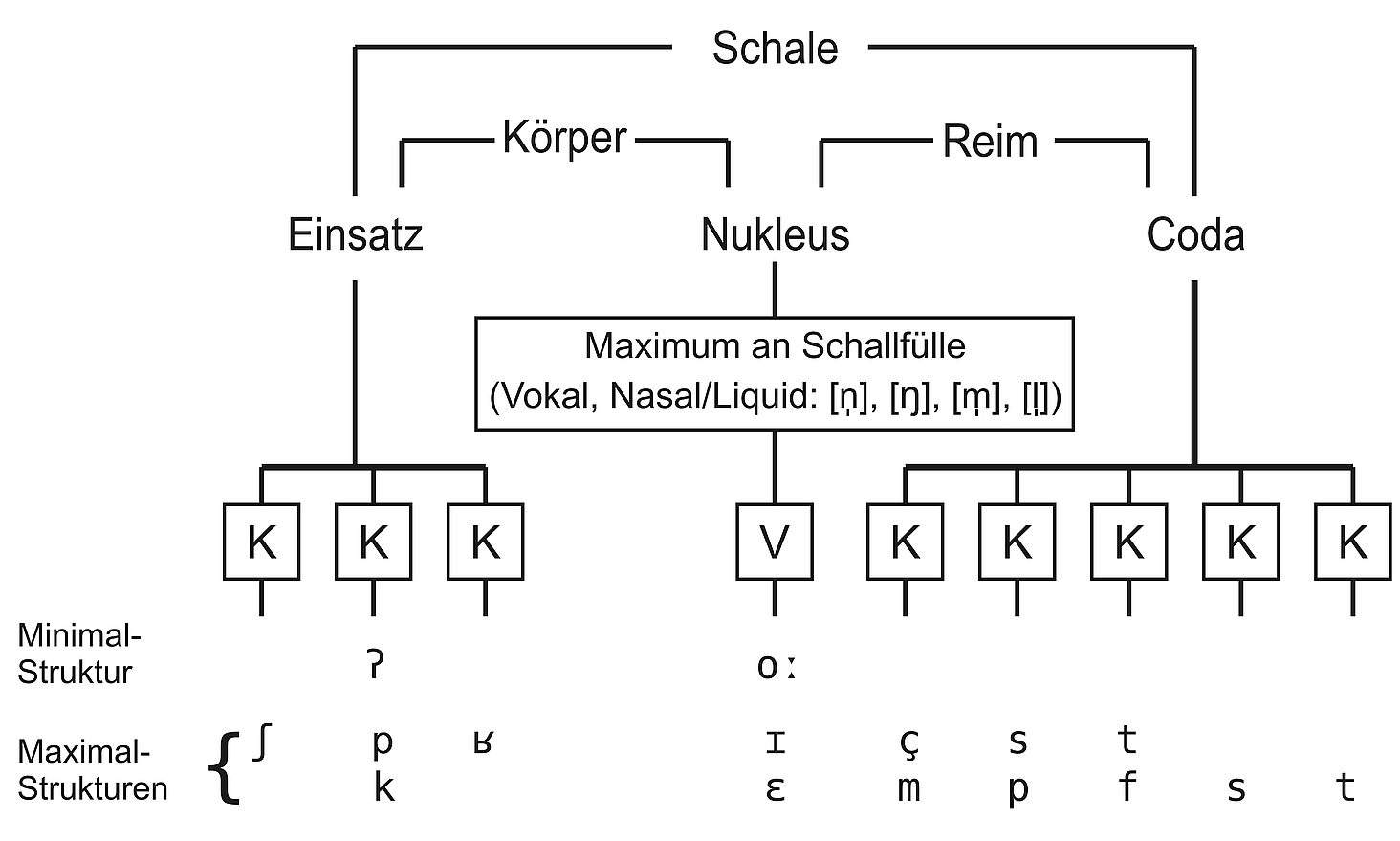
Dem Nukleus vorausgehende Konsonanten bezeichnet man als „Einsatz“, ihm folgende Konsonanten als „Coda“. Einsatz und Nukleus werden zusammenfassend auch als „Körper“, Nukleus und Coda als „Reim“ einer Silbe bezeichnet.
Zur Beschreibung des Silbenaufbaus einer Sprache wird jeweils die minimale und maximale Anzahl der Vokale (V) und Konsonanten (K) angegeben, die eine Silbe umfassen kann. Einen sehr einfachen Silbenbau zeigt (B2).
Die Silben der betreffenden Sprache bestehen demnach minimal aus einem Vokal. Maximal umfassen sie eine Konsonant-Vokal-Verbindung. Der Konsonant wird durch Klammerung als optional gekennzeichnet. Ein entsprechender Silbenbau findet sich im Deutschen bei Interjektionen, z. B. ah [Ɂaː]; zudem in Wörtern wie du, Vieh etc.
Hat eine Sprache (fast) ausschließlich solche einfachen Silben, entsteht ein Problem: Aufgrund der Begrenztheit des Phoneminventars ist die Anzahl unterscheidbarer Silben des Bautyps KV vergleichsweise gering und führt bei einem Wortschatz mit Tausenden von Wörtern zu zahlreichen Homonymen, also formgleichen Wörtern mit ganz verschiedenen Bedeutungen, wie oben am Beispiel von chinesisch ma gezeigt.[ 3 ] Um das Problem zu reduzieren, sind zwei Möglichkeiten denkbar: Zum einen können zwei oder mehr einsilbige Wörter zu größeren Einheiten kombiniert werden. Zum anderen kann der Silbenbau durch Ausbau der konsonantischen Silbenränder (Einsatz und Coda) um komplexere Strukturen erweitert werden.
Wenn der Einsatz einer Silbe durch ein Element ausgefüllt wird, spricht man von einer „gedeckten“ Silbe. Wird er das nicht, spricht man von einer „ungedeckten“ Silbe. Je nachdem, ob die Coda gefüllt ist, unterscheidet man zwischen offenen (codalosen) und geschlossenen Silben.
Komplexere Baustrukturen von Silben werden im Deutschen ausgiebig eingesetzt (s. Abb. 1). Die Sprache ist durch eine Tendenz zu gedeckten geschlossenen Silben gekennzeichnet. Sowohl der Einsatz als auch die Coda sind oft ausgebaut. Maximal umfasst die Silbe drei Konsonanten im Einsatz (Beispiel: (du) sprichst [ʃpʁɪçst]) und fünf Konsonanten am Silbenende (Beispiel: (du) kämpfst [kɛmpfst]).[ 4 ] In Komposita (z. B. Kampfstreik) und über Wortgrenzen hinweg können daher gegebenenfalls bis zu sechs oder sieben Konsonanten aufeinander folgen (z. B. bei (T2) ![]() Du trinkst Sprudel).
Du trinkst Sprudel).
In manchen Fällen ist es nicht ganz einfach zu bestimmen, welcher Laut als Silbengrenze anzusetzen ist. Dies gilt im Deutschen z. B. für Wörter wie Sommer, rennen, Welle usw., bei denen sich zwei Silben einen Konsonanten zu „teilen“ scheinen. In (B4) stehen mehrere Möglichkeiten der Silbengliederung nebeneinander. Die mit (*) markierten erscheinen aufgrund der Tendenz des Deutschen zu gedeckten und geschlossenen Silben als rhythmisch unvollständig.
Konsonanten, die zwei Silben angehören, bezeichnet man als „ambisyllabisch“. Sie finden sich im Deutschen nach kurzen Vokalen. Die Doppelschreibung der Konsonanten wird daher nicht nur als orthographisches Prinzip zur Kennzeichnung von Vokalkürze, sondern als Verschriftlichung der silbischen Verhältnisse betrachtet.[ 5 ]
Offene und geschlossene Silben sind im Deutschen mit der Vokallänge verbunden. Betonte offene Silben gehen immer mit dem Auftreten von Langvokalen oder Diphthongen einher (z. B. sie [zi:], seh.e [ˈzeːə], Abenteuer [ˈɁaːbm̩tɔʏ̯ɐ]). Bei geschlossenen Silben, deren Coda mehr als einen Konsonanten enthält – sog. Mitlauthäufungen –, bilden hingegen Kurzvokale den Silbenkern (z. B. Rost [ʁɔst], kalt [kalt], Hand [hant]). Scheinbare Ausnahmen von dieser Regel bilden Wörter wie wohnt, kühlst etc. Die im Infinitiv und generell im Basismorphem vorhandene Vokallänge ([voːn] in wohnen) wird von den Konsonanten der Verbflexionsmorpheme nicht beeinflusst.[ 6 ]
Die Frage, in welchen Kombinationen Laute Silben konstituieren können, ist Gegenstand der Phonotaktik.[ 7 ] Im Blick auf die Reihenfolge, in der Laute verschiedenen Typs in Silben auftreten, wird von einer universalen [ 8 ] „Sonoritätshierarchie“ ausgegangen, wobei außer Vokalen auch andere stimmhafte Laute sonor sind bzw. Sonorität besitzen. Das allgemeine Prinzip ist hier: Der Einsatz einer Silbe ist durch zunehmende, der Kern durch maximale, die Coda durch abnehmende Sonorität gekennzeichnet (Abb. 2).
Abb. 2: Sonoritätshierarchie der Silbe

Nasallaute sind sonorer als Obstruenten, Reibelaute sonorer als Plosive, so dass sich die Abfolgen Plosiv-Reibelaut im Anlaut, Nasal-Reibelaut-Plosiv im Auslaut ergeben. Viele deutsche Wörter folgen dieser Sonoritätshierarchie (z. B. Brand, planst, s. Abb. 2). Allerdings wird die Sonoritätshierarchie nicht immer durchgehalten. Es findet sich im Einsatz z. B. auch die Abfolge Reibelaut-Plosiv-Reibelaut (z. B. Straße). Auch können Reibelaute im Reim der Silbe auf Plosive folgen, z. B. bei Genitivkonstruktionen wie (des) Worts, was die Annahme „extrasyllabischer“ Konsonanten begründet.
Ausgehend von der Schallfülle des Nukleus wird in einigen phonologischen Arbeiten zum Deutschen zwischen einem „scharfen“ oder „starken“ Silbenschnitt, bei dem die Klangfülle des Vokals unterbrochen wird, und einem „weichen“ bzw. „schwachen“ Silbenschnitt, bei dem die Klangfülle des Vokals langsam abnimmt, unterschieden. Offene betonte Silben erfordern einen schwachen Silbenschnitt, d. h. sie werden lang ausgesprochen. Für geschlossene betonte Silben ist der scharfe Silbenschnitt, d. h. ein Kurzvokal charakteristisch. Das Merkmal „Länge“ wird bei einer solchen Beschreibung also nicht als phonologische Eigenschaft der Vokale aufgefasst, sondern als phonotaktisches Moment gewertet. Zur Erfassung von Länge wird in einigen Ansätzen ein zeitliches Maß, nämlich die Einheit More verwendet. Bei Langvokalen setzt man dann einen Umfang von zwei Moren, bei Kurzvokalen einen Umfang von einer More an.
Je nach Beschaffenheit des Silbenkerns wird zwischen „schweren“ und „leichten“ Silben unterschieden. Als schwere Silben werden Silben bezeichnet, deren Kern aus Langvokal oder Diphthong besteht oder die eine Coda besitzen. Als leichte Silben werden Silben ohne Coda bezeichnet, deren Kern ein Kurzvokal bildet, sowie solche, die mit Reduktionsvokal oder als konsonantische Silbe realisiert werden.
Schwere Silben sind im Deutschen potenzielle Akzentstellen, d. h. sie können betont werden. Leichte Silben werden hingegen nur dann akzentuiert, wenn im Wort keine schweren Silben vorhanden sind (s. Kap. 14.3.1).
Die Silbenstruktur hängt eng mit dem morphologischen Bau der Sprache zusammen und steht in engem Zusammenhang mit den Wortakzentuierungen. Theisen (2016) spricht in diesem Zusammenhang von „Wortsprachen“ und „Silbensprachen“. In Silbensprachen (z. B. Italienisch, Griechisch) kann die Akzentuierungsstelle bei Wörtern wechseln; der Akzent kann dabei auch auf Silben fallen, die die Flexionsendung tragen. Die Silben sind häufig offen, Volltönigkeit der Vokale ist in allen Silben gegeben. In Wortsprachen wie dem Deutschen hat sich demgegenüber eine feste, semantisch begründete Akzentuierung entwickelt. Die Nebensilben werden abgeschwächt, verlieren (tendenziell) ihre vokalischen Kerne und schließen sich der vorhergehenden Silbe an. Der Prozess lässt sich als Sprachentwicklungstendenz zur Monosyllabik verstehen, aus der im Rahmen langfristiger Sprachwandlungsprozesse eine Übereinstimmung von Silbe und Wort resultiert (vgl. Kap. 2.2). Extrasyllabische Konsonanten sind hierbei eine „Durchgangsstufe“.
14.2.2 Der Silbenaufbau im Sprachvergleich
Die Strukturen der Silben in verschiedenen Sprachen können sich stark unterscheiden. Konsonantenhäufungen in Einsatz und Coda sind für verschiedene Sprachen charakteristisch, z. B. auch für die slawischen Sprachen. Im Tschechischen lässt sich sogar ein ganzer „vokalloser Satz“ bilden.[ 9 ] Viele andere Sprachen sind demgegenüber durch einen häufigeren Wechsel von Vokalen und Konsonanten gekennzeichnet. (B6) zeigt einen türkischen Beispielsatz: Eve gidiyorum (Ich gehe nach Hause):
Lernenden mit anders strukturierten Herkunftssprachen bereiten die Konsonantencluster [ 10 ] des Deutschen häufig Schwierigkeiten. Sie fügen manchmal zusätzliche Vokale ein, um die Cluster aufzulösen („Sprossvokale“). Oft hat der Sprossvokal eine Funktion als „Stützvokal“, der einen konsonantischen Wortanfang umwandelt. Bei Lernenden mit der Herkunftssprache Spanisch treten solche Stützvokale z. B. vor [ʃp] auf (Tonbeispiel (T3) ![]() ). In der gesprochenen Lernersprache sind Sprossvokale oft unauffällig. Sie zeigen sich aber in schriftlichen Produktionen und sind den Lernenden entsprechend bewusst zu machen. (B7) zeigt – neben weiteren Phänomenen [ 11 ] – solche Sprossvokale im Text einer tunesischen Schreiberin.
). In der gesprochenen Lernersprache sind Sprossvokale oft unauffällig. Sie zeigen sich aber in schriftlichen Produktionen und sind den Lernenden entsprechend bewusst zu machen. (B7) zeigt – neben weiteren Phänomenen [ 11 ] – solche Sprossvokale im Text einer tunesischen Schreiberin.
ich bene teraur one maein geschew
ister saein. abir maein geschewister
biben Alle in Tunisein ich ben
Fero wein maein Familie Alle sich
wein ich nachaus Fahrin
Ich bin traurig, ohne meine Geschwis-
ter zu sein. Aber meine Geschwister
blieben alle in Tunesien. Ich bin
froh, wenn ich meine Familie alle sehe,
wenn ich nach Hause fahre.
14.3 Akzentuierung
Unter Akzentuierung bzw. Akzent [ 12 ] versteht man die wahrnehmungstechnische Hervorhebung einer Silbe als „betont“. Die akustischen Korrelate von Akzentuierung im Deutschen sind vielfältig:
- Veränderung der Tonhöhe,
- stärkerer Druck,
- höhere Lautstärke sowie
- Länge / Quantität.
Auf die Hervorhebung einer Silbe durch Tonhöhenveränderung bezieht man sich auch mit dem Terminus „musikalischer Akzent“. Die Hervorhebung durch Druck wird auch als „dynamischer Akzent“ bezeichnet. Historisch gab es im Germanischen einen Übergang vom musikalischen zum dynamischen Akzent, der u. a. zur Herausbildung des Flexionstyps der schwachen Verben führte (vgl. Kap. 2.2). Im heutigen Deutsch sind meist mehrere Momente an der Hervorhebung einer Silbe beteiligt: Es findet sich als Realisierung des Akzents eine Kombination aus veränderter Tonhöhe, stärkerem Druck, höherer Lautstärke und gegebenenfalls Länge.
14.3.1 Akzentuierung von Wörtern
Jedes mehrsilbige Wort hat mindestens eine Akzentstelle, d. h. eine Silbe, die gegenüber anderen hervorgehoben wird. Für das Deutsche ist dabei ein starker Kontrast zwischen schweren und leichten Silben kennzeichnend.
Die GdS formuliert die Akzentregeln des Deutschen unter Rückgriff auf das Konzept der Silbenschwere (s. Kap. 14.2) folgendermaßen: Treten eine leichte und eine schwere Silbe in einem Wort auf, so fällt der Akzent auf die schwere Silbe. Treten nur leichte oder nur schwere Silben auf, so erhält die erste Silbe den Akzent. Treten mehrere schwere und leichte Silben auf, so fällt der Akzent auf die erste schwere Silbe mit einer Folgesilbe ohne Akzentstelle. Demzufolge stellt sich die Betonung von Wörtern wie Segel oder Abenteuer so dar:
Auf Wörter, die aus anderen Sprachen übernommen wurden (z. B. Balkón, Temperamént), treffen diese Regeln jedoch nicht immer zu.
Für Lehrzwecke des Deutschen erweist sich eine Regelformulierung ausgehend von semantischen Kriterien als praktikabler. Mehrsilbige Wörter entstehen im Deutschen zum einen durch Flexionsformen (z. B. ge-, -en), zum anderen durch das Verfahren der Wortbildung mittels angefügter unselbstständiger Morpheme wie be-, ver-, zer-, er-, -heit, -keit, -haft. Bezüglich der Akzentuierung gilt, dass diejenige Silbe betont wird, die den Vokal des Wortstamms trägt („Stammprinzip“). Die Stammsilbe vermittelt die wichtigste semantische Information und wird daher gegenüber den anderen hervorgehoben bzw. die anderen Silben werden ihr gegenüber abgeschwächt.
Im Unterschied zu Sprachen, bei denen ein so genannter „gebundener Wortakzent“ vorliegt, der ein regelmäßiges Betonungsschema vorsieht (z. B. Erstbetonung, wie es im Tschechischen oder Ungarischen der Fall ist), spricht man im Falle des Deutschen daher von einem „freien Wortakzent“, der durch semantische Kriterien begründet auf verschiedene Silben fallen kann.
Die Platzierung des Akzents kann im Deutschen auch Wörter voneinander differenzieren. Dies betrifft allerdings nur einige zusammengesetzte Verben und Adjektive sowie Wortübernahmen aus dem Lateinischen:
Verschiebungen im Wortakzent, die durch morphologische Prozesse bedingt sind, kommen im Deutschen zwar vor, sind aber auf Lehnwörter beschränkt.
Bei zusammengesetzten Wörtern (z. B. Buchhandel, Fahrkartenkontrolle) finden sich im Deutschen neben einem „Hauptakzent“ häufig noch ein oder mehrere schwächer realisierte „Nebenakzente“. In IPA werden Hauptakzente durch [ˈ], Nebenakzente durch [ˌ] jeweils vor der akzentuierten Silbe notiert. Die Hauptbetonung im zusammengesetzten Wort trägt immer das Bestimmungswort. Das Grundwort behält seine Betonung je nach Sprechtempo und -rhythmus als Nebenakzent bei. Tritt das Bestimmungswort als zweiter Konstruktionsbestandteil auf, trägt es entsprechend die Hauptbetonung.
Bei Mehrfachkomposita können je nach Setzung des Hauptakzents unterschiedliche semantische Gewichtungen vorgenommen werden (B14). Während in (B14a) durch den Hauptakzent auf Trainer im Wort Trainerfindungskommission [ 13 ] hervorgehoben wird, dass es der Trainer (und nicht ein Spieler) ist, den man sucht, wird (B14b) durch Hauptakzent auf findungs das Finden als Prozess in den Fokus der Aufmerksamkeit gerückt.
Bei einem so genannten „Kontrastakzent“ wird die normale Wortakzentuierung verschoben, um ein bestimmtes Moment vergleichend hervorzuheben:
In der Gesamtäußerung stellt die Einzelwortakzentuierung lediglich ein Akzentuierungspotenzial bereit, das durch andere Momente überformt wird:
- durch den Sprechrhythmus (Taktung)
- durch Bezugnahme auf Erwartungsstrukturen des Hörers (Gewichtung)
- durch die intonatorische Globalkontur der Äußerung (Melodieverlauf, Intonation i.e.S.)
Manche Wortakzente werden gegebenenfalls weiter „eingeschmolzen“, d. h. mehr oder weniger stark realisiert; andererseits werden manchmal auch monosyllabische Wörter akzentuiert.
14.3.2 Rhythmus und Gewichtung
Die rhythmische Einheit „Takt“ umfasst eine betonte Silbe und ihr vorausgehende und folgende unbetonte Silben, deren Anzahl variieren kann. Für das Deutsche wird von einer Anzahl von bis zu vier unbetonten Folgesilben pro Takt ausgegangen.
abɐˈdaˌʃteˑnzofiləˈlɔʏ̯tə|dɛsveːŋˈglaʊ̯bɪçˈɁɛsɪçˈhɔˑʏ̯tədiː
gəˈʃmoɐ̯tn̩ˈɁaʊ̯stɐnˌpɪltsə|vaɪ̯ldasɪsˈɁaʊ̯χvɛgəˈtaːʁɪʃǁ]
Die Aussprache der Silben wird an die Taktung angepasst: Je größer die Anzahl der inakzentuierten Silben ist, umso kürzer werden sie realisiert, was u. a. zu Vokalreduktionen und anderen Tilgungen führt. Anders als z. B. Französisch, Italienisch oder Finnisch, die zu den silbenzählenden Sprachen gerechnet werden, wird Deutsch daher als akzentzählende Sprache bezeichnet.
Die Taktung erfolgt im Deutschen nach semantischen Kriterien. Dabei werden verschiedene Akzentuierungsgrade genutzt, d. h., es wird nicht nur zwischen „betonten“ und „unbetonten“, sondern auch zwischen „stärker“ und „weniger stark“ betonten Silben differenziert. Weniger „wichtige“ semantische Einheiten werden durch schnelleres Sprechen und Zusammenziehungen in den Hintergrund gerückt, während bestimmte sinntragende Einheiten durch stärkere Hervorhebung in den Vordergrund treten. Der Schwerpunkt liegt im Deutschen gewöhnlich auf Symbolfeldausdrücken (Nomina, Verben, Adjektive). Zurückgestuft (und in Abfolgen schneller gesprochen) werden demgegenüber operative und deiktische Prozeduren (Funktionswörter wie Konjunktionen, phorische Prozeduren, Sprecher- und Hörerdeixis), es sei denn, sie unterliegen einer eigenen semantischen Fokussierung.
Die Schwerpunktsetzung nach semantischen Gesichtspunkten wird als „Gewichtungsakzent“ (traditionell „Satzakzent“) bezeichnet. Die hervorgehobene Silbe wird manchmal auch „Fokusakzentsilbe“ genannt. Innerhalb einer Äußerung wird durch Akzentuierung mindestens ein Schwerpunkt gesetzt, d. h. mindestens ein inhaltliches Moment in den Aufmerksamkeitsfokus gebracht. Es können jedoch auch mehrere Momente fokussiert werden. Eine Äußerung wie Hast du Mut? beispielsweise lässt sich mit verschiedenen Gewichtungsakzenten realisieren:
In (B17b) und (B17c) werden über den unmarkierten Fall, einem Gewichtungsakzent auf dem Nomen Mut (B17a), hinaus noch weitere inhaltliche Momente thematisiert. Während die erwarteten thematischen Folgehandlungen von (B17a) Ausführungen dazu betreffen, was Mut haben im vorliegenden Zusammenhang bedeutet, zeigt der Gewichtungsakzent auf der Hörerdeixis du in (B17b) eine Entgegensetzung an (eine andere Person hat keinen Mut bewiesen). In (B17c) wird durch den Gewichtungsakzent auf hast eine zweifelnde Rückfrage ausgedrückt.
Auf die Reichweite eines Gewichtungsakzents bezieht man sich mit den Termini Hervorhebungsdomäne oder Akzentdomäne. Die Akzentdomäne eines Gewichtungsakzents kann der propositionale Gehalt des Einzelworts sein, auf dem er realisiert wird.[ 14 ] Das Einzelwort kann jedoch auch „Exponent“ einer größeren Einheit sein (z. B. Wortgruppe, Satz), deren gesamter propositionaler Gehalt durch den auf dem Einzelwort realisierten Gewichtungsakzent fokussiert wird.[ 15 ]
Die Wahl der Mittel (Tonhöhensprung nach oben oder unten, Druck, Länge) bei der differenzierenden rhythmischen Schwerpunktsetzung geschieht im Zusammenspiel mit der Intonation, dem Melodieverlauf der Äußerung, und wird häufig mit demselben Beschreibungsapparat erfasst.
14.4 Globale Tonhöhenverläufe
Im Folgenden geht es um die über einen längeren Zeitraum hinweg wahrgenommenen Tonhöhenveränderungen einer Äußerung, die insbesondere in fremdsprachendidaktischen Kontexten auch als Sprechmelodie bezeichnet werden. Bei dem älteren Terminus „Satzintonation“ ist zu beachten: Äußerungen der gesprochenen Sprache können zwar Satzcharakter annehmen, sind jedoch nicht immer mit der Einheit Satz identisch. Es finden sich in der gesprochenen Sprache z. B. häufig Ausrufe wie Asoziale Typen!, Formeln wie Herzlichen Glückwunsch zum Geburtstag! oder Einwortäußerungen (danke), die ausgehend von einem Satzkonzept „unvollständig“ erscheinen.
In den Tonhöhenverlauf einer Äußerung fließen die Verfahren der Akzentuierung ein. Phonologisch relevante Formen lassen sich vor allem für den Endverlauf der Tonbewegungen bestimmen.
14.4.1 Zur Notation von Tonhöhenverläufen
Bei der Erfassung des Tonhöhenverlaufs einer Äußerung können kontinuierlich abbildende und punktuell notierende Verfahren unterschieden werden, mit denen die wahrnehmbare Tonhöhenveränderung wiedergegeben wird.
Abb. 3: Intonationsnotation in der GdS (nach Zifonun / Hoffmann / Strecker 1997, S. 193)
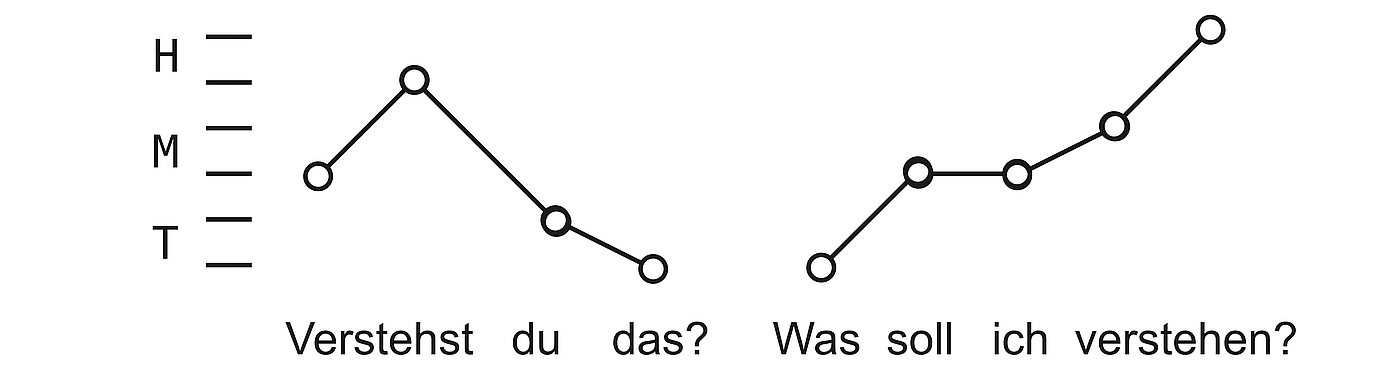
Ein kontinuierlich abbildendes Verfahren in der akustischen Phonetik ist die graphische Wiedergabe des Grundfrequenzverlaufs (F0) in einem Frequenz-Zeit-Diagramm (vgl. Kap. 13). In der auditiven Notation werden für das Deutsche hingegen oft punktuell notierende, silbenorientierte Verfahren gewählt, die verschiedene Tonhöhen durch eine notenähnliche graphische Wiedergabe erfassen. Dabei geht man von einer relativen Skala von 4 bis 6 Tonhöhen aus, die zur Beschreibung der auf deutschen Äußerungen realisierten Tonverläufe erforderlich sind. Zum Teil werden noch weitere Merkmale der Akzentuierung notiert und Gewichtungsakzente durch Unterstreichung gekennzeichnet. Die GdS wählt ein silbenorientiertes Notationsverfahren. Die Duden-Grammatik notiert demgegenüber die Tonhöhe nur für Zielpunkte der Tonbewegung.[ 16 ]
14.4.2 Beschreibungsansätze
Globale Verlaufskonturen von Äußerungen („Melodieverläufe“) sind in der Linguistik zumeist als Satzintonation thematisiert worden, wobei oft analog zu den Begriffen „Phonem“ und „Graphem“ die Begriffe „Melodem“ oder „Intonem“ verwendet werden.[ 17 ] Die globalen Melodieverläufe stehen funktional in Bezug zu verschiedenen Satztypen bzw. Illokutionen und sind teilweise nur mit Blick auf längere Diskursabschnitte erklärbar.
In Beschreibungen der deutschen Intonation finden sich unterschiedliche Ansätze. Während in einigen Arbeiten als Bezugseinheit von vornherein der Satz gesetzt wird, gehen andere Ansätze von einer rhythmischen Einheit aus, die einen oder mehrere Takte umfasst und die als „Tongruppe“ oder „Intonationsphrase“ bezeichnet wird. Tongruppen bzw. Intonationsphrasen können unterschiedlichen syntaktischen Größen entsprechen (von der Minimaleinheit „Wort“ bis hin zu einer längeren Äußerung bzw. komplexen Satzkonstruktion). Zwischen Akzentuierung und Satzintonation wird bei dieser Auffassung dann nicht unterschieden.
Die in der jeweiligen intonatorischen Einheit enthaltene Silbe mit der stärksten Prominenz wird als „Schwerpunktsilbe“ oder „Iktus“ bezeichnet [ 18 ]. Unakzentuierte Silben (Begleittöne) können ihr als Vorlauf vorausgehen oder als Nachlauf folgen. Die für eine Intonationsphrase bzw. Tongruppe charakteristische Tonhöhenveränderung muss nicht auf der Schwerpunktsilbe erfolgen, sondern kann auch prä-iktisch oder post-iktisch realisiert werden.
Bei der Beschreibung von Intonation im Deutschen lassen sich levelorientierte Ansätze und konturorientierte Ansätze unterscheiden. Die Duden-Grammatik unternimmt eine levelorientierte intonatorische Beschreibung ausgehend von zwei relativen Tonhöhen, hoch (high, H) und tief (low, L). Dabei differenziert sie zwischen Akzenttönen, die an Akzentsilben gebunden sind (H*, L*), ihren Begleittönen (H, L) sowie Grenztönen, die die Grenzen der Intonationsphrase markieren (Hι, Lι). Im Folgenden wird der konturorientierte Beschreibungsansatz der GdS näher erläutert, der die Endtonverläufe von Äußerungen näher fokussiert.
Die Endtonverläufe einer Äußerung lassen sich phonologisch in fallende (terminale), steigende (interrogative) und weiterverweisende (progrediente) Tonverläufe einteilen, die mit verschiedenen Satztypen (Aussagesatz, Fragesatz, Satz mit folgendem Nebensatz) verbunden sind. Die Bezeichung „interrogativ“ darf allerdings nicht so verstanden werden, dass im Deutschen alle Fragesätze mit einem steigenden Tonverlauf verbunden sind.
14.4.3 Fallende Endtonverläufe
Ein fallender Endtonverlauf liegt im Deutschen in zwei intonatorischen Verlaufsformen vor, einer einfach fallenden und einer steigend-fallenden. Bei einer einfach fallenden Verlaufsform – die GdS spricht hier von einem Falltonmuster – fällt der Stimmton von einem höheren Level, einem hohen Mittelton oder einem Hochton, auf eine tiefe Stufe ab.
Abb. 4: Falltonmuster (nach Zifonun / Hoffmann / Strecker 1997, S. 193)

Bei der steigend-fallenden Variante (Gipfeltonmuster) steigt der Stimmton von einer tiefen Ausgangslage auf ein höheres Level an und sinkt anschließend wieder auf ein tieferes Niveau ab. Anfangs- und Endlevel der Bewegung können dabei unterschiedlich sein.
Abb. 5: Gipfeltonmuster (nach Zifonun / Hoffmann / Strecker 1997, S. 194)

Fallende Endtonverläufe zeigen an, dass die Information, die durch die Intonationsphrase vermittelt wird, dem gemeinsamen Wissen von Sprecher und Hörer hinzuzufügen ist und als abgeschlossen betrachtet wird. Sie sind oft bei Assertionen, z. B. bei Antworten auf Fragen, zu beobachten und finden sich zudem im Zusammenhang mit Aufforderungen, Wünschen, Ausrufen und vorangestellten Anreden.
Auch Fragen sind im Deutschen oft mit fallendem Endtonverlauf verbunden. Charakteristisch ist ein solcher Tonverlauf für Ergänzungsfragen und für geschlossene Alternativfragen [ 19 ].
Entscheidungsfragen sind demgegenüber typischerweise mit steigendem Tonverlauf verbunden. Als markierte, sekundäre Variante ist jedoch auch die Realisierung mit fallendem Tonverlauf möglich. (B20) gibt ein Beispiel aus einem Unterrichtsgespräch.
Fallende Verläufe treten typischerweise bei Fragen auf, mit denen an Vorhergehendes angeknüpft wird und die der Rethematisierung eines bereits behandelten Gesprächsgegenstands dienen.
14.4.4 Steigende Endtonverläufe
Ein steigender Endtonverlauf findet sich im Deutschen als einfach steigende Verlaufsform (Steigtonmuster), in einer fallend-steigenden Verlaufsform (Taltonmuster) sowie als doppelte Steigung (Doppelsteigtonmuster).
Bei einem einfach steigenden Tonverlauf steigt die Stimmtonlage von einem mittleren oder tiefen Level auf eine höhere Stufe an.
Abb. 6: Steigtonmuster (nach Zifonun / Hoffmann / Strecker 1997, S. 193)

Bei einem Taltonmuster wird die Stimme hingegen zunächst auf eine tiefere Lage abgesenkt, um dann auf eine höhere Lage zu steigen.
Abb. 7: Taltonmuster (nach Zifonun / Hoffmann / Strecker 1997, S. 194)

Steigende Endtonverläufe sind im Deutschen charakteristisch für Entscheidungsfragen und offene Alternativfragen [ 20 ].
Sie finden sich ferner im Zusammenhang mit Bestätigungsfragen.
In einer markierten, sekundären Verwendung kommen steigende oder fallend-steigende Verläufe auch bei Ergänzungsfragen vor:
Fragen mit steigendem Akzent legen laut Duden-Grammatik im Unterschied zu Fragen mit fallendem Akzent eine ausführlichere Antwort nahe.
Auch Nachfragen können mit steigendem oder fallend-steigendem Tonverlauf geäußert werden. Typisch für Nachfragen ist laut GdS jedoch die Realisierung mit Doppelsteigtonmuster. Bei dieser Verlaufsform wird der Ton zunächst auf eine höhere Lage angehoben, um dann nochmals eine Steigerung zu erfahren. Inhaltlich zeigt ein solcher Tonverlauf Überraschung des Sprechers an.
Abb. 8: Doppelsteigtonmuster (nach Zifonun / Hoffmann / Strecker 1997, S. 195)

Die Duden-Grammatik sieht einen steigenden Endtonverlauf ferner als typisch für Aufzählungen an und erfasst damit auch Fälle, die von der GdS dem Typus „progredienter Tonverlauf“ zugeschrieben werden, der auch mit einer leichten Steigung verbunden sein kann.
14.4.5 Progrediente Endtonverläufe
Unter der Bezeichnung „Mitteltonmuster“ und als <→> notiert fasst die GdS verschiedene Tonverlaufsmöglichkeiten zusammen, die traditionell als „progredienter Tonverlauf“ bezeichnet werden. In einer möglichen Variante verbleibt der Tonverlauf auf einer mittleren Lage oder sinkt auf das mittlere Tiefniveau ab. Eine andere Variante ist durch eine Steigung auf das mittlere Hochniveau gekennzeichnet.
Abb. 9: verschiedene Mitteltonmuster (nach Zifonun / Hoffmann / Strecker 1997, S. 194)

Progrediente Endtonverläufe dienen der Kennzeichnung von Binnengrenzen syntaktischer Konstruktionen innerhalb einer kommunikativen Minimaleinheit und besitzen sowohl abgrenzende als auch koordinierende Funktion. Sie finden sich zwischen Phrasen, Teilsätzen, sowie vor und nach Parenthesen. Charakteristische Verwendungszusammenhänge sind Aufzählungen und Reihungen. Ergänzende Nebensätze (Supplementsätze) werden oft mit progredientem Tonverlauf angeschlossen. Ein typischer Einsatzbereich insbesondere der leicht steigenden Variante ist die Assertionsverkettung, z. B. bei Erzählungen. Der Tonverlauf zeigt dann die geplante Weiterführung der Äußerung an.
Unterschiedliche Anschlussmöglichkeiten zwischen Äußerungen und Äußerungsteilen sind:
- das Verfahren der Juxtaposition (Nachstellung) ohne Konjunktor, aber mit intonatorischer Progredienz,
- das Verfahren der Koordination mittels Konjunktor, mit oder ohne Progredienz, sowie
- das Verfahren der Quasi-Koordination, das die Realisierung eines (steigenden oder fallenden) Grenztonmusters mit der Koordination durch einen Konjunktor verbindet.
14.5 Prosodische Phänomene und Gestik
Ein bestimmter Typus von Gesten [ 21 ] ist eng mit der Äußerungsprosodie verbunden. Man bezeichnet solche Gesten als Taktstockgesten (beats, batons). Taktstockgesten besitzen eine zweigliedrige Struktur (onset / stroke). Der Einsatz dieses Gestentyps geschieht zeitlich synchron zu Hervorhebungen der Einheit Silbe.
Abb. 10 gibt ein Beispiel für den Einsatz von Taktstockgesten in einer Rede im Deutschen Bundestag. Strokes werden in den Abbildungen durch Pfeile erfasst. Die Klammerung in der Verbalzeile erfasst die zeitliche Parallelität von Wort und Beat.
Abb. 10: Taktstockgesten (batons, beats) in einer Bundestagsrede [ 22 ]
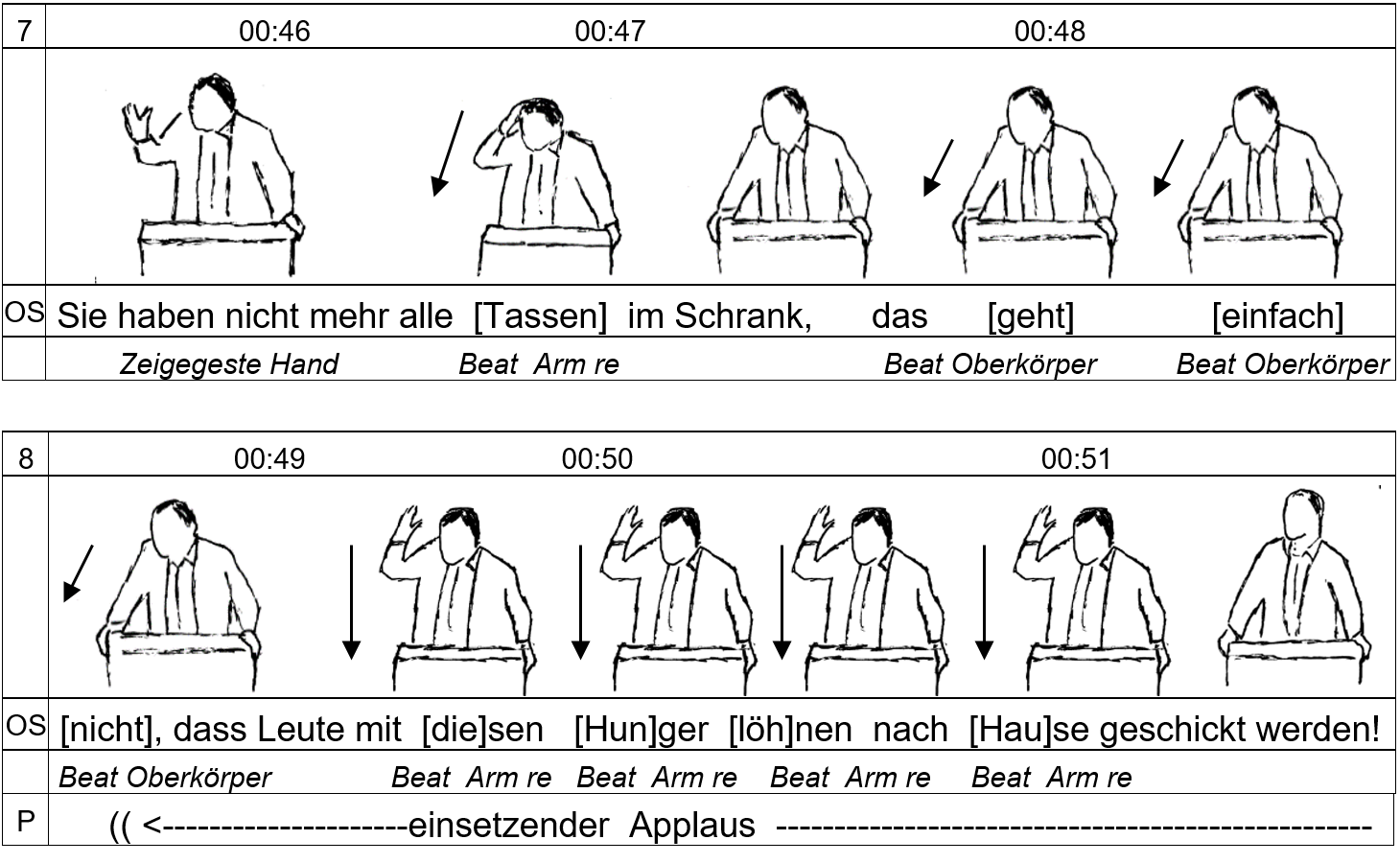
Als visuelle Akzentuierungen verstärken Taktstockgesten die akustisch-auditiven Hervorhebungen von sinntragenden Wörtern und dienen somit der visuellen Informationsstrukturierung ebenso wie einer Verstärkung der illokutiven Kraft der Äußerung (s. Kap. 15). Der Einsatz von beats ist mit dem auditiven Kontinuum laut-leise verbunden: ein zunehmender Einsatz geht oft mit einer Erhöhung der Äußerungslautstärke einher.
Die enge Verbindung der Gestik zur artikulatorisch-auditiven Dimension legt es nahe, das Untersuchungsgebiet von Phonetik und Phonologie um die visuelle Perspektive zu erweitern, nicht zuletzt, da auch die Mimik akustisch-auditive Entsprechungen besitzt, die in gegenwärtigen diskursanalytischen Transkriptionen mit erfasst werden (vgl. Kap. 4). Z. B. ist ein Lachen oder Schluchzen auditiv ebenso wie visuell erkennbar.
14.6 Prosodie als Thema für Deutsch als Fremd- und Zweitsprache
Prosodische Phänomene werden seit geraumer Zeit als Lerngegenstand für Deutsch als Fremd- und Zweitsprache angesprochen. Befragungen wie die von Ortmann (1976) haben gezeigt, dass für Deutschlernende vieler Herkunftssprachen vor allem die Konsonantenhäufungen am Silbeneinsatz und in der Silbencoda schwierig sind. Ein in diesem Zusammenhang auftretendes Kontaktphänomen, das Auftreten von Sprossvokalen, wurde bereits angesprochen.
Experimentelle Untersuchungen wie die von Hirschfeld (1994) haben zudem aufgewiesen, dass Deutschlernende bei vortragendem Sprechen schlechte Verständnisleistungen erzielten, obwohl sie in Einzelwortrealisierungen als „gut verständlich“ eingestuft worden waren. Gegenüber muttersprachlichen Vorträgern ließ sich ein Informationsverlust von rund 30 % verzeichnen. Vermutet werden kann, dass dieses Ergebnis auf die prosodische Äußerungsrealisierung zurückzuführen ist.
In zahlreichen Arbeiten zum Deutschen als Fremdsprache werden rythmisch-intonatorische Muster als Lernproblem und Lerngegenstand angesprochen, oftmals kontrastiv (vgl. die bei Hirschfeld / Reinke 2007 versammelten Beiträge). Interessante Beobachtungen, die z. T. durch empirische Untersuchungen belegt werden konnten, liegen z. B. für russische Deutschlerner vor: Der in der russischen Sprache üblicherweise genutzte Frequenzumfang (z. B. im Kontext von Fragen) ist größer als im Deutschen, wo eine entsprechende Erhöhung der Tonfrequenz die Äußerung als emotional bzw. emphatisch markiert. Russische Deutschlernende übertragen oftmals die russischen Tonkonturen auch in das Deutsche.[ 23 ] Die Übertragung prosodischer Strukturen auf die Fremd- oder Zweitsprache Deutsch birgt erhebliche Missverstehenspotentiale, die insbesondere die illokutive Kraft der Äußerung, ihre Wirkung auf den Hörer, betreffen.[ 24 ]
Über die in verschiedenen Sprachen vorfindliche Verbindung von Stimmqualität und Emotionsausdruck weiß man gegenwärtig noch wenig. Eine Forschergruppe um Klaus Scherer und Harald Walbott konnte in einer experimentellen Studie, die in insgesamt neun Ländern (Deutschland, (französischsprachige) Schweiz, Großbritannien, Niederlande, USA, Italien, Frankreich, Spanien und Indonesien) durchgeführt wurde, nachweisen, dass Emotionen wie Ärger, Traurigkeit, Angst und Freude sowie eine neutrale Stimmlage über alle Sprachen hinweg zu rund 66 % aus dem Stimmklang professioneller deutscher Sprecher zutreffend erkannt werden.[ 25 ] Zwar konnten auch deutsche Probanden nicht alle Emotionen korrekt einordnen (so wurden beispielsweise Angst und Traurigkeit verwechselt); es zeigte sich aber, dass größere Sprachdistanz mit einer schlechteren Erkennungsrate einherging. Für Indonesien betrug die Erkennungsquote beispielsweise nur 52 % (Scherer / Banse / Walbott 2001). Das Geschlecht der Probanden erwies sich als nicht signifikant. Als über die Sprachen hinweg relativ stabil erwiesen sich die auftretenden Verwechslungen. In allen Ländern erzielte die Erkennung von „Freude“ die schlechtesten Ergebnisse.
Die bisherigen Ergebnisse weisen darauf hin, dass im Blick auf die Umsetzung von emotionalen Qualitäten erhebliche Sprachdifferenzen bestehen, die sich auch im Kontext Deutsch als Fremdsprache auswirken.[ 26 ] In Lehrwerken wird die Äußerungsintonation allerdings bislang eher selten angesprochen. Häufiger hingegen finden sich Übungen zur Wortintonation. Bei der Vermittlung wird auch die enge Verbindung der körperlichen Grob- und artikulatorischen Feinmotorik genutzt: didaktische Verfahren umfassen hier u. a. den gezielten Einsatz von Taktstockgesten.
[ 1 ]Zudem finden sich im Moselfränkischen so genannte „Tonakzente“, die Wörter wie mehr und Meer voneinander unterscheiden (vgl. Schmidt / Herrgen 2011, S. 170). Die prosodische Struktur wird von Nicht-Rheinländern oft als „rheinischer Sing-Sang“ wahrgenommen.
[ 2 ]„Unterlagern“ oder „durchdringen“ wären ebenso passende Charakterisierungen (Ternes 1999, S. 113).
[ 3 ]Vgl. Theisen (2016, S. 67).
[ 4 ]Eine solche Fünferstruktur wird allerdings oft reduziert ([kɛmfst]), vgl. Kohler (1995).
[ 5 ]Der Duden spricht hier von „Gelenkschreibung“. Silbentheoretisch spricht man bei einer solchen konsonantischen Doppelbindung auch von einem „festen Anschluss“, dem der „lose Anschluss“, bei dem sich kein gemeinsames konsonantisches Element in einer Silbenabfolge findet (z. B. De.gen versus dek.ken), gegenübergestellt wird (s. u. a. Maas 2006).
[ 6 ]Maas (1999), Hall (2010) und Theisen (2016) sehen darin morphologisch bedingte Randkonsonanten, die früher zu silbischen Morphemen gehörten, nämlich -et und -est. Sie sprechen auch von „extrasyllabischen Konsonanten“.
[ 7 ]Die Konfixe -taktik und -taxe gehen auf gr. τάξις (Ordnung) zurück, entsprechend auch Syntax.
[ 8 ]Im Sinne von sprachlichen Universalien verstanden; zur Universalienforschung im Blick auf Silbenstrukturen und zu verschiedenen Auffassungen von „Sonorität“ s. Hall (2000), Maas (2004).
[ 9 ]Strč prst skrz krk! (Steck den Finger in den Hals!), s. Błaszczak, Joanna (2014) Das Polnische und das Tschechische. In: Krifka et al (Hg.), S. 67–92, 74.
[ 10 ]Cluster ([ˈklastɐ]), Clusterung = gehäuftes Auftreten eines Elements.
[ 11 ]Probleme bereiten der Schreiberin u. a. die Groß- und Kleinschreibung, die Kennzeichnung von Vokallänge und Vokalkürze sowie die Worttrennung. Die maschinenschriftliche Umsetzung lässt zudem einige Details nicht erkennen. Schramm (1996) druckt den Text im handschriftlichen Original ab. Sieht man die handschriftliche Umsetzung, fallen auch weitere Unsicherheiten auf, z. B. in Bezug auf die Differenz zwischen <e> und <i> (Weglassen des i-Punktes).
[ 12 ]„Akzent“ bezeichnet hier also nicht die hörbare „Fremdheit“ eines Fremdsprachensprechers.
[ 13 ]Eine solche Kommission wurde vom Präsidenten des Deutschen Fußballbunds (DFB), Gerhard Mayer-Vorfelder, nach Absage von Ottmar Hitzfeld als Trainer der deutschen Nationalmannschaft 2004 eingerichtet.
[ 14 ]Die GdS spricht dann von einem „lokalen Gewichtungsakzent“.
[ 15 ]Die GdS spricht dann von einem „kompositionalen Gewichtungsakzent“.
[ 16 ]Sie geht dabei von „intonatorischen Tönen“ aus, die gegen „lexikalische Töne“ (Toneme) abgegrenzt werden.
[ 17 ]S. z. B. von Essen (1964).
[ 18 ]Einige Ansätze sprechen hier auch von der „Nukleussilbe“, „Tonsilbe“ oder dem „Akzentton“. Bei den Begleittönen wird zwischen den vorausgehenden „Leittönen“ und angeschlossenen „Folgetönen“ differenziert.
[ 19 ]Zu offenen und geschlossenen Alternativfragen s. Kap. 15. Geschlossene Alternativfragen erfragen eine Wahl zwischen zwei Alternativen; mögliche Antworten sind Tee oder Kaffee, nicht jedoch ja bitte.
[ 20 ]In offenen Alternativfragen gelten die genannten Alternativen nur als Beispiele (Paraphrase: „Möchten Sie etwas trinken?“); mögliche Antworten sind z. B. ja, bitte; nein, danke; Haben Sie auch ein Wasser? usw.
[ 21 ]Zum Begriff Gestik s. genauer Kap. 16.5.
[ 22 ]Redner: Ottmar Schreiner, 29.09.2011.
[ 23 ]Mehrere Beiträge in Hirschfeld/Reinke (2007) beschäftigen sich mit diesem Thema.
[ 24 ]Vgl. auch Liedke (2007).
[ 25 ]Genutzt wurden dabei sprachähnliche, aber semantisch sinnlose Äußerungen, die aus phonologischen Formen verschiedener Sprachen zusammengesetzt waren (“meaningless multilanguage sentences”, z. B. “Hat sundig pron you venzy.”, Scherer / Banse / Walbott 2001, S. 79).
[ 26 ]Auch eine Studie von Missaglia (2001) mit italienischen Deutschlernern weist auf Erkennungsprobleme emotionaler Stimmqualitäten hin.